论文阅读:Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
摘要
这篇论文是关于语义计算模型的,尽管我们可以使用词袋、word2vec、doc2vec等语义表示,但是这些都是浅层表示,我们可以基于深度学习,来进行更深层次的语义表示。
通常的搜索引擎的匹配都是基于关键字的,很多时候效果是不好的。我们可以将查询语句和文档都映射到同一个低纬空间,然后通过计算距离来衡量相关性。
模型的训练是基于点击链接数据,极大化给定query条件下,被点击的文档的条件似然。
为了让模型可以应用到大规模的网页搜索程序从,使用了word hashing技术来处理大的词汇表。
论文中的模型在真实场景中进行了评估,并取得了比现在先进的模型更好的结果。
简介
关键字匹配通常是不准确的,因为同一个意思可以用不同的词汇表达。
最近,有两个方向来扩展语义计算模型。
首先,可以利用点击链接数据:有一连串的查询和对应的点击文档组成。
其次,可以使用深层的自动编码模型。
在这篇论文中,结合上述两种方式,提出了Deep Structured Semantic Models(DSSM)。
和之前语义计算模型(非监督)不同的是在于我们的模型直接优化在网页内容排序上。
相关工作
点击数据与隐语义模型
深度学习方法
LSM和点击数据使用
- 线性投影模型(LSA)
- 翻译模型(使用点击数据)
深度学习
自编码
问题:
优化方式是通过重建,而不是比较相关性
性能较差,只能处理2000词汇表
针对网页的DSSM
针对语义特征计算的DNN
网络结构图如下:
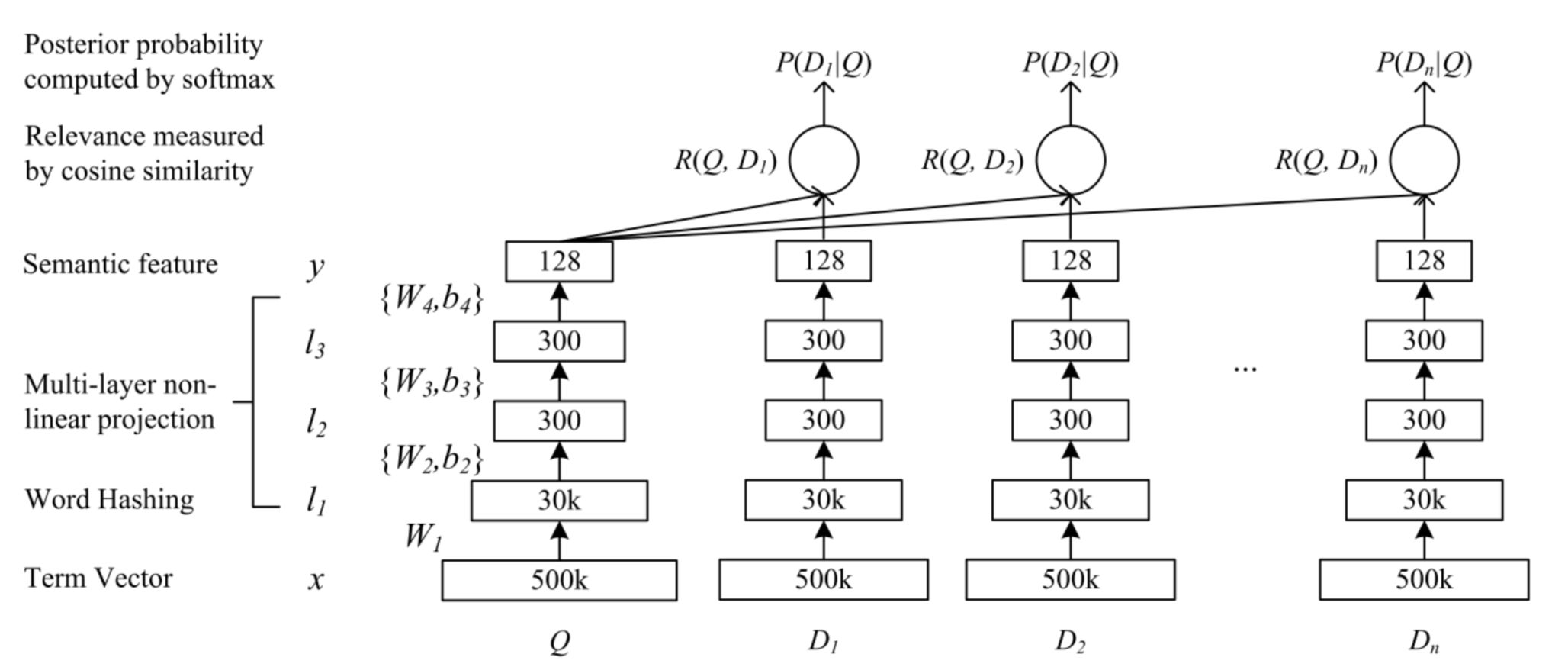
图中的计算公式如下:
激活函数使用tanh
总体来说, 网络结构还是比较简单的。
第一层采用的就是word hashing技术。
Word Hashing
目标是为了降低bag-of-words的特征维度。
基于n-gram技术。
举个例子:
给定单词:good,首先在首尾添加‘#’,变成‘#good#’,然后在n=3时分为:#go, goo, ood, od#。
问题之一是可能存在冲突,即不同的单词有着相同的切分,但是冲突数量很小。
优点:
- 英语单词的数量是无限的,但是letter n-gram经常是有限的
- 一个单词的不同变形在letter n-gram空间通常比较接近
- 基于word的表示很难处理新词,letter n-gram可以
Word Hashing可以看做一种固定的线性变化。
DSSM学习
在点击数据日志中选取文档正样本,然后再选取4个负样本,以最大化被点击的文档的条件似然为目标函数,使用梯度下降算法进行训练学习。
实现细节
为了防止过拟合,将数据切分为训练集和验证集,且二者没有交集。
梯度下降时使用小批量(1024个样本)随机梯度下降算法。
实验
在网页文档排序任务上使用真实世界数据集进行DSSM的评估。
总结
主要贡献在于在3个方面扩展了之前的隐语义模型。
- 使用点击数据来训练参数
- 使用深度学习框架,将线性语义模型扩展到非线性
- 使用基于letter n-gram的word hashing技术,可以将模型应用到很大的词汇表数据中
以上三个方面,单个方面就有很好的提升。结合在一起就达到最好的结果。